Il y a toujours plusieurs façons de modéliser des données : certaines sont meilleures que d’autres. L’un des principaux critères est la présence ou non de redondance dans la modèle. Pour nous aider à différencier la qualité de deux modèles donnés, des critères ont été créés, appelés formes normales.
Jusqu’à maintenant, nous avons souvent parlé de redondance, mais sans réellement formaliser de règle. Les formes normales vont combler ce manque. ;)
Appréhendez la notion de dépendance
Réfléchissons un peu plus sur la question de la redondance, en nous basant sur votre fichier CSV :

Ici, vous avez par exemple une redondance sur le type d'œuvre. L’information selon laquelle Fleabag des studios Banijay est une série TV est présente plusieurs fois. Pourquoi ? Parce que le type d'œuvre ne dépend que de l'œuvre. Or dans le fichier, il y a beaucoup de lignes qui concernent une même œuvre : l’information est donc dupliquée.
Quand vous dites « le type d’oeuvre ne dépend que de l’oeuvre », cela signifie que dans le fichier, si vous voyez « Fleabag des studios Banijay », alors le type sera forcément « Série TV ».
Seulement, qu’est-ce qui permet d'identifier une œuvre dans votre fichier ? On en a déjà parlé : on identifie une œuvre par son titre et sa société de production, soit (titre, societe_prod).
On dit donc que type_de_tournage dépend fonctionnellement du groupe d’attributs (titre, societe_prod) . Cela s’appelle une dépendance fonctionnelle. Elle se note avec une flèche :
(titre, societe_prod) -> type_de_tournage
Seulement voilà : dans votre fichier, le groupe(titre, societe_prod) n’est pas unique : plusieurs lignes correspondent à une même œuvre. S’il y a plusieurs fois la même œuvre, alors il y aura, à cause de la dépendance fonctionnelle, plusieurs lignes qui indiquent de quel type est une œuvre donnée. Et il y aura donc de la redondance.
Conclusion : pour éviter la redondance, il faudrait que (titre, societe_prod) soit unique. Donc que ce groupe d’attributs soit une clé primaire (ou tout au moins une clé candidate). Voici donc ce que vous pouvez en conclure :
Petit complément : si un attribut dépend d’une partie de la clé primaire, il y a tout de même risque de redondance. Imaginons une table dont la clé primaire serait(titre, societe_prod), et un attributadresse_societe_prod donnant l’adresse postale de la société de production.
adresse_societe_prod dépend uniquement desociété_prod . Comme societe_prod n’est pas unique (car ce n’est qu’une partie de la clé primaire), alors il y a quand même risque de redondance :
Titre [PK] | Société de production [PK] | Adresse société prod |
Rocky bat le boa | Pathé-en-croûte productions | 361 rue de la Boucherie, 87000 Limoges |
Fast and Curious | Pathé-en-croûte productions | 361 rue de la Boucherie, 87000 Limoges |
Vous pouvez donc compléter la phrase précédente par :
Sachez déterminer une dépendance
Mais au fait, comment être sûr qu’un attribut A dépend d’un groupe d’attributs G ?
Imaginez que vous connaissiez parfaitement les données que vous modélisez. Posez-vous cette question : en ne connaissant que G, puis-je déterminer de manière certaine A, sans ambiguïté, et sans avoir besoin d’autre information ?
Par exemple :
Pouvez-vous déterminer le type de tournage (Téléfilm, Série TV, etc.) d’une œuvre en ne connaissant que sa société de production ? La réponse est non, car une société de production peut avoir produit plusieurs œuvres de types différents. Il y a donc une ambiguïté, et pour la résoudre il vous faut une information en plus : le titre de l’œuvre. Avec le titre et la société de production, vous pouvez déterminer le type de tournage, si vous connaissez sur le bout des doigts vos données. On peut donc dire que :
type_de_tournagene dépend pas uniquement desociete_prod;type_de_tournagedépend de(titre, societe_prod).
Oui, mais si je connais le titre, la société de production et le lieu de tournage d’un tournage donné, je peux aussi déterminer type_de_tournage . Peut-on dire que type_de_tournage dépend de (titre, societe_prod, localisation_de_la_scene) ?
Oui, mais ce n’est pas très intéressant, car (titre, societe_prod, localisation_de_la_scene) n’est pas minimal, c’est-à-dire que l’on peut enlever l’un des attributs ( localisation_de_la_scene ) sans casser le lien de dépendance. On dira alors que :
type_de_tournagedépend d’une partie de(titre, societe_prod, localisation_de_la_scene).
Déduisez-en les trois premières formes normales
Le raisonnement que vous venez de mener a été formalisé sous forme de trois règles, appelées formes normales. Il en existe plus que trois, mais on considère en général qu’une modélisation qui respecte ces trois premières formes évite déjà une très grande partie de la redondance qui peut se cacher dans les données.
La 1NF
La première forme normale est un prérequis aux deux suivantes. Comme on parle de clés primaires, il faut que :
Chaque table ait une clé primaire ;
Chaque attribut ne contienne qu’une seule information à la fois (sinon c’est rapidement le bazar dès qu’il s’agit de contrôler la redondance d’information ou l’unicité d’un attribut).
Autrement dit, chaque attribut doit être atomique, c’est-à-dire qu’il ne doit être ni multivalué ni composite (pour vous rafraîchir la mémoire sur ces deux termes, faites un tour au premier chapitre de la partie 2 : « Posez les premières briques de votre diagramme de classes »).
attribut composite |
| attributs atomiques |
| => |
|
Regardons l’exemple ci-dessous. ;)
Dans notre fichier, la colonne realisateur_ice est multivalué, car une seule cellule contient parfois deux noms de réalisateurs.
Par exemple la ligne
2019-1450: Lise Akoka et Romane Gueret.
Intuitivement, vous avez bien pris en compte ceci dans votre modèle relationnel, car vous avez transformé cet attribut multivalué en une nouvelle table realisateur_ice , contenant un attribut nom qui est atomique (et c’est bien !). Cette nouvelle table est liée avec la table oeuvrepar une association plusieurs-à-plusieurs :
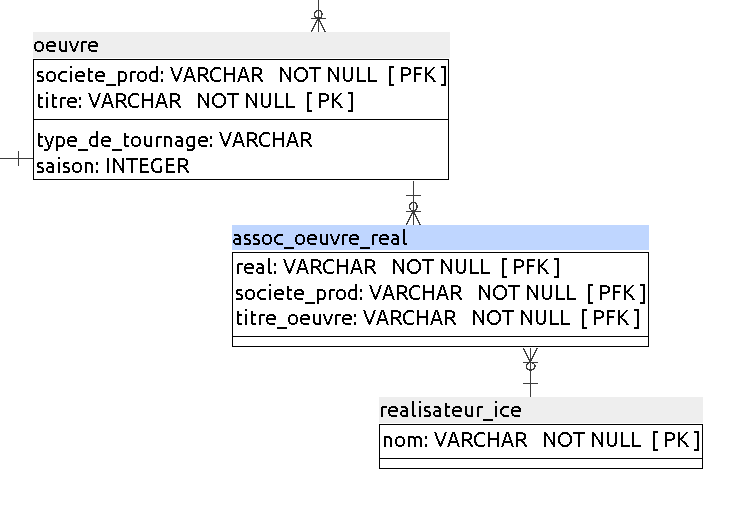
La 2NF
La deuxième forme normale découle de la réflexion que vous avez menée plus haut :
Une table est en 2NF si :
Elle est en 1NF ;
Et si tout attribut (n’appartenant pas à une clé candidate) ne dépend pas d'une partie seulement d’une clé candidate.
La 3NF
Une relation est en 3NF si :
Elle est en 2NF ;
Et si tout attribut (n'appartenant pas à une clé candidate) ne dépend pas d'un autre attribut n'appartenant pas à une clé candidate.
Apprenez à respecter les trois formes normales
Pour respecter la 1 NF, il vous faut :
Choisir une clé primaire pour chaque table ;
Transformer les attributs multivalués en une nouvelle table liée avec la table d’origine par une association un-à-plusieurs ou plusieurs-à-plusieurs ;
Décomposer les attributs composites en des attributs atomiques (exemple : décomposer « Mme Jeanne Herry » en trois attributs civilité, nom, prénom).
Pour les 2NF et 3NF, il faut étudier les dépendances entre les attributs.
Pour vous aider, il y a une règle pour « séparer » les attributs d’une table pour réduire la redondance ET ne pas perdre d’information. La voici :
Aussi, si un autre attribut B dépend également uniquement de G, alors il faut aussi le déplacer dans la nouvelle table T2 !
Par exemple, dans votre fichier CSV, vous avez vu que type_de_tournage dépend de ( titre, societe_prod). De plus, ce groupe est minimal. On peut donc appliquer la règle ci-dessus avec :
T1 = votre fichier CSV ;
A =
type_de_tournage;G =
(titre, societe_prod).
En suivant cette règle,
On crée T2 dont la clé primaire est
(titre, societe_prod), et qui contient comme attributtype_de_tournage.On supprime la colonne
type_de_tournagedu gros fichier CSV.On indique que
(titre, societe_prod)est une clé étrangère qui référence T2.
Et là… surprise ! Vous vous rendez compte que T2 correspond tout à fait à la tableoeuvre que vous avez définie précédemment !
titre [PK] | societe_prod [PK] | type_de_tournage |
Fleabag | Banijay Studios France | Série TV |
Munch saison 3 | JLAPRODUCTIONS | Série TV |
Madame Claude | Les Compagnons du Cinéma | Long métrage |
C’est bon signe, cela signifie que, sans le savoir, vous étiez sur la bonne voie quand vous avez déterminé votre modèle relationnel !
La question est maintenant de savoir : aurions-nous abouti au même modèle relationnel si nous avions suivi cette procédure jusqu’au bout ? C’est-à-dire en séparant successivement le gros fichier CSV en différentes tables ?
Eh bien… vous allez vous-même réfléchir à la réponse dans quelques secondes ! De plus, c’est cette procédure que vous allez appliquer au chapitre suivant, quand vous allez séparer votre fichier CSV en différentes tables.
Séparez votre fichier
Ce que je vous propose, c’est de considérer que votre fichier CSV est une table, puis de la séparer en plusieurs tables en analysant les dépendances entre les attributs. Il faudra utiliser la règle citée ci-dessus.
Mais avant de commencer, il faut déterminer la clé primaire de votre gros fichier.
Facile ! Chaque ligne est identifiée par la colonneidentifiant_du_lieu, c’est donc la clé primaire !
Ce n’est pas faux, effectivement… Mais cela ne va pas nous mener très loin ! En effet, avec ce raisonnement vous tombez dans le piège cité tout en bas du chapitre « Déterminez vos clés primaires ». Pour rappel, ce piège consiste à considérer une clé artificielle (par exemple identifiant_du_lieu) comme une solution de simplicité, sans réfléchir à la contrainte d’unicité des autres attributs.
En effet, c’est la clé primaire qui vous renseigne sur la nature de chacune des lignes de la table.
Instinctivement, vous auriez pu vous dire « Chaque ligne est identifiée par la colonne identifiant_du_lieu », chaque ligne est donc un lieu. Or c’est faux : il y a parfois plusieurs lignes qui correspondent à un même lieu, par exemple les lignes 2016-1817et 2016-1622. Il y a donc moins de lieux que de lignes dans votre fichier.
La colonne identifiant_du_lieu n’est donc pas un identifiant du lieu, mais plutôt un identifiant de sessions de tournage d’une œuvre donnée, sur un lieu donné, sur une période donnée. Autrement dit, c’est l’identifiant d’une association entre :
Un lieu (identifié par
localisation_de_la_sceneetcode_postal)Et une période de tournage (identifiée par
date_de_debut) d’une œuvre (identifiée partitreetsociete_prod).
Vous pouvez donc déduire que l’une des clés primaires possibles est (localisation_de_la_scene, code_postal, date_de_debut, titre, societe_prod) .
À partir de cette information, tout attribut qui ne dépendra pas de cette clé primaire, ou qui n’en dépendra que d’une partie, pourra être déplacé dans une nouvelle table !
À vous de jouer !

Vous avez toutes les clés en main pour déduire un modèle relationnel à partir des colonnes de votre fichier !
En guise de réponse, je vous donne les dépendances entre les attributs :
(
titre,societe_prod) ->type_de_tournage.(
date_de_debut) ->annee_du_tournage. Cet attribut est inutile car dérivé.(
localisation_de_la_scene,code_postal) -> (latitude,longitude) . C’est certes discutable, mais nous considérerons ici qu’il n’y a qu’un seul couple lat/long pour une adresse donnée.(
titre,societe_prod,date_de_debut,date_de_fin) →realisateur_ice.
Sur les points 1 à 3, tout correspondait à ce que vous aviez trouvé avant ce chapitre. Mais pour le point 4, c’est différent : en effet, on s’aperçoit que le réalisateur d’une œuvre ne dépend pas que de l’oeuvre en question, mais aussi de la période de tournage.
En effet, il arrive que des réalisateurs se succèdent au cours de la réalisation d’une œuvre. C’est souvent le cas pour les séries, dans lesquelles chaque épisode est parfois réalisé par des personnes différentes.
Par exemple pour la série « Munch », réalisé par Thierry BINISTI en juillet 2019 et par Laurent TUEL en mai 2019 .
Si vous regardez le modèle relationnel que vous aviez jusqu’au chapitre précédent, vous n’aviez pas moyen de savoir quel réalisateur dirigeait le tournage d’une période donnée. En d’autres termes, même si vous pouviez connaître les réalisateurs de « Munch », vous n’aviez plus moyen de savoir que les tournages de mai 2019 ont été dirigés par Laurent TUEL.
Pour résoudre cela, il faut appliquer la règle donnée ci-dessus et créer une table dont la clé primaire est ( titre, societe_prod,date_de_debut , date_de_fin), et qui contient un attribut realisateur_ice . Cette table donne des périodes de tournage d’une œuvre donnée (mais sans indication de lieu). On l’appeleraperiode_de_tournage.
De plus, la colonne « Réalisateur/Réalisatrice » de votre fichier est multivalué, car certaines lignes contiennent des couples de réalisateurs (voir la ligne2019-407). Comme nous l’avions dit plus haut dans ce chapitre, vous pouvez donc le décomposer en une nouvelle table appelée realisateur_ice, qui est liée àperiode_de_tournage par une association plusieurs-à-plusieurs, comme ceci :
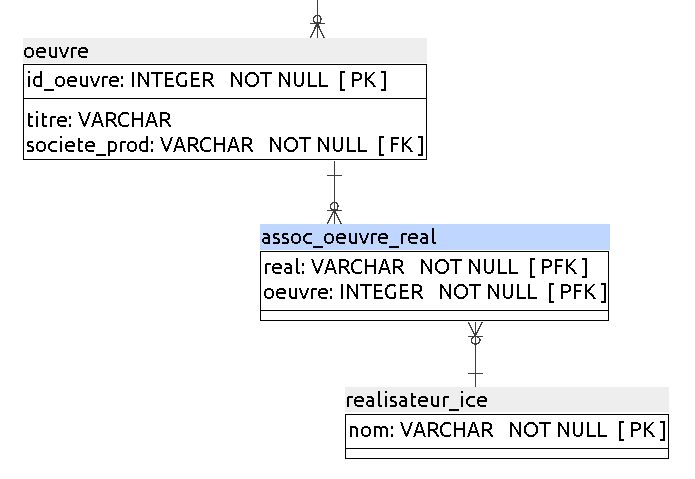
À la fin, quand vous aurez séparé toutes les tables, il ne vous restera plus que :
id_lieu;Une clé étrangère vers
lieu, composée de deux colonnes ;Une clé étrangère vers
periode_de_tournage, composée de quatre colonnes.
Vous pouvez supprimer id_lieu: il ne sert plus à rien. Cette table a tout à fait la forme d’une table d’association entre lieu et periode_de_tournage: et ça tombe bien, car une table d’association signifie une association plusieurs-à-plusieurs. Or :
Un tournage peut se réaliser à la même période sur deux lieux différents (avec deux équipes différentes ou avec une équipe qui se déplace dans la même journée) ;
Un lieu peut accueillir différents tournages sur une même période !
Appelons donc cette tableassoc_periode_lieu.
Youpi ! Vous avez maintenant votre modèle relationnel définitif, qui est en 3NF !
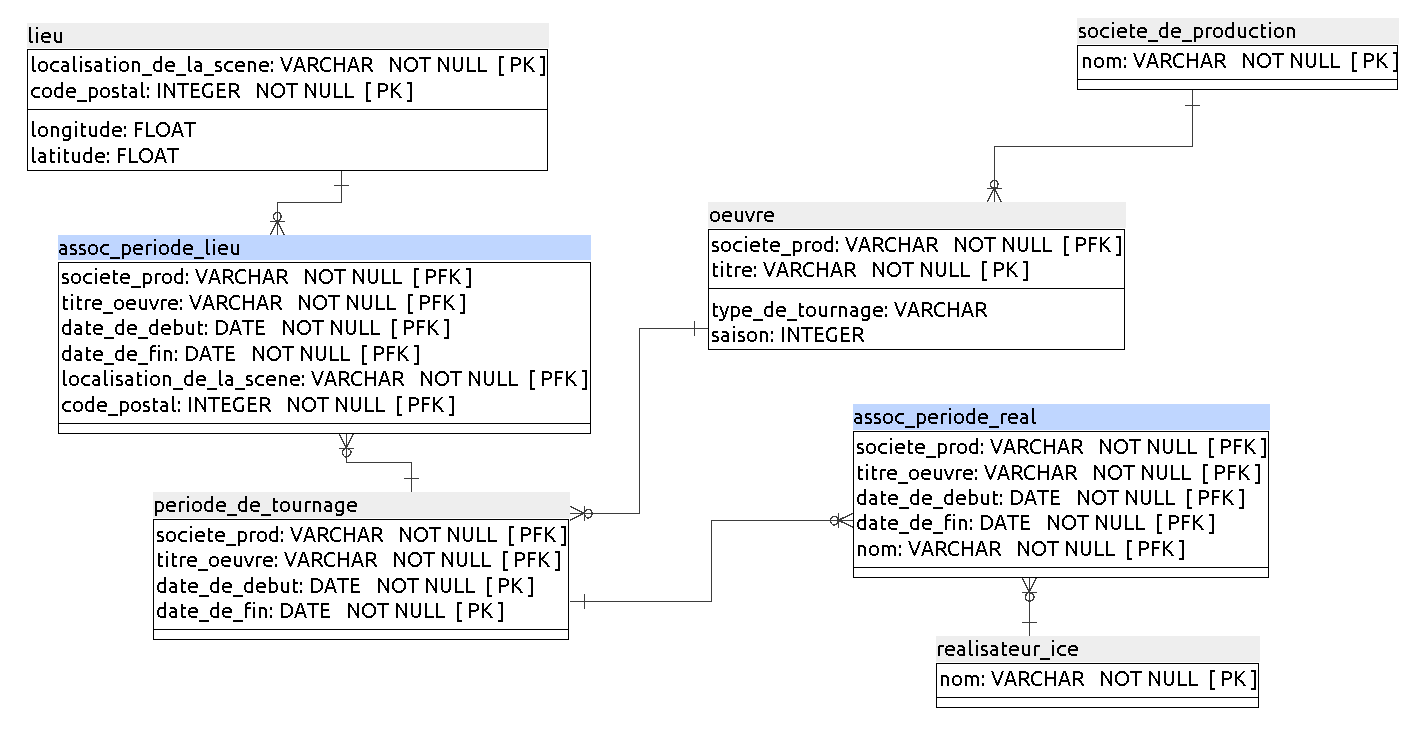
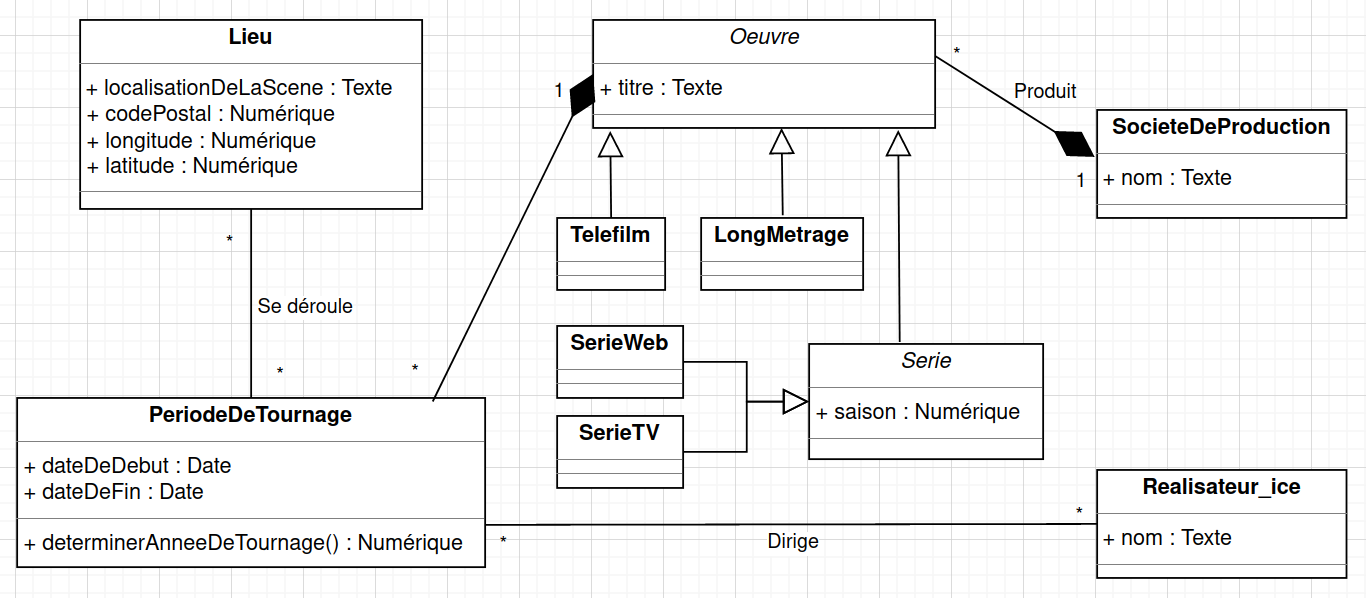
En résumé
Certains attributs peuvent dépendre d'autres attributs.
Pour éviter (une bonne partie) de la redondance dans une table, il faut que chaque attribut (qui n’appartient pas à la clé primaire) ne dépende que de la clé primaire de la table. De plus, un attribut doit dépendre de l'ensemble de la clé primaire.
Une table est en 1NF si elle possède une clé primaire et si tous ses attributs sont atomiques.
Une table est en 2NF si elle est en 1NF et si tout attribut (n’appartenant pas à une clé candidate) ne dépend pas d'une partie seulement d’une clé candidate.
Une relation est en 3NF si elle est en 2NF et si tout attribut (n'appartenant pas à une clé candidate) ne dépend pas d'un autre attribut n'appartenant pas à une clé candidate.
Il y a une règle pour « séparer » les attributs d’une table pour réduire la redondance ET ne pas perdre d’information.
Après la normalisation d'une modélisation relationnelle, il faut penser à actualiser l'UML en conséquence.
Voilà, vous avez acquis toutes les compétences nécessaires à la modélisation d’une BDD relationnelle !
