Faisons le point sur l'avancée de notre enquête !
Précédemment, nous avons trouvé deux intermédiaires qui sont liés à Big Data Crunchers Ltd. Pour rappel, les intermédiaires, ce sont des personnes, des banques ou des cabinets d'avocats qui aident, qui demandent ou qui réalisent eux-mêmes la création de sociétés. Parfois, ces sociétés sont des sociétés-écrans enregistrées dans des paradis fiscaux.
Est-ce le cas des 2 intermédiaires que nous avons trouvés ? Leur activité est-elle suspecte ?
Pour le savoir, nous allons utiliser un type de requête SQL qui s'appelle l'agrégation.
Découvrez l'agrégation
À quoi sert l'agrégation ?
On utilise l'agrégation lorsque l'on veut calculer un résultat qui porte sur plusieurs lignes d'une table. On dit que l'on agrège ces lignes, c'est-à-dire que l'on forme des agrégats pour effectuer sur eux une opération.
Prenons la question suivante :
Combien de sommiers de chaque modèle sont présents dans l'entrepôt ?
Ici, il y aura un agrégat par modèle. Il s'agit alors de calculer une valeur pour chaque agrégat :
le nombre de sommiers pour le modèle Toukonfor ;
le nombre de sommiers pour le modèle Nuipésible ;
le nombre de sommiers pour le modèle Ferdodo,
etc.
Ceci peut se résumer par un tableau :
modèle | nombre de sommiers |
Toukonfor | 30 |
Nuipésible | 23 |
Ferdodo | 25 |
Vous sentez déjà l'importance de l'agrégation, n'est-ce-pas ?
Pour faire une belle agrégation, il faut deux étapes, et donc deux ingrédients :
Un groupe de colonnes de partitionnement.
Une (ou des) fonction(s) d'agrégation.
Partitionnez vos données
Pour illustrer cette partie, reprenons les Panama Papers.
Nous allons utiliser 3 colonnes de la table entity :
jurisdiction: la juridiction auprès de laquelle la société a été créée. Le plus souvent, la juridiction est un pays ;status: le statut de la société (au moment de la publication des Panama Papers) : est-elle active ? inactive ? dissoute ? en liquidation ? etc. Rassurez-vous, pas besoin de connaître la signification de ces termes : je ne les maîtrise pas moi-même ;lifetime: durée de vie de sociétés : c'est le nombre de jours durant lesquels la société a été active, depuis sa création jusqu'à sa date de dissolution.
Voici un aperçu de ces colonnes :
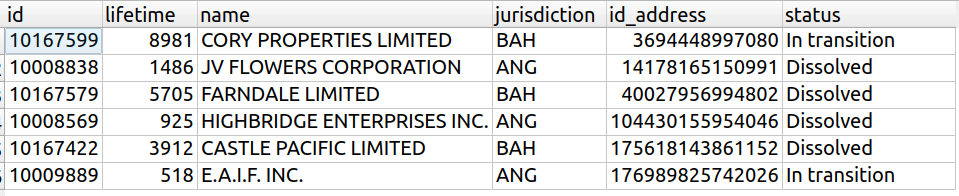
Si je choisis de partitionner les sociétés par juridiction, cela signifie que je veux former des groupes de sociétés, tels que toutes les sociétés d'un même groupe doivent être de la même juridiction. On appelle ces groupes des agrégats.
Je peux également partitionner sur plusieurs colonnes. Par exemple, je peux partitionner mes sociétés par les colonnes jurisdiction et status. Ainsi, au sein d'un même groupe de sociétés, la juridiction et le statut seront identiques :
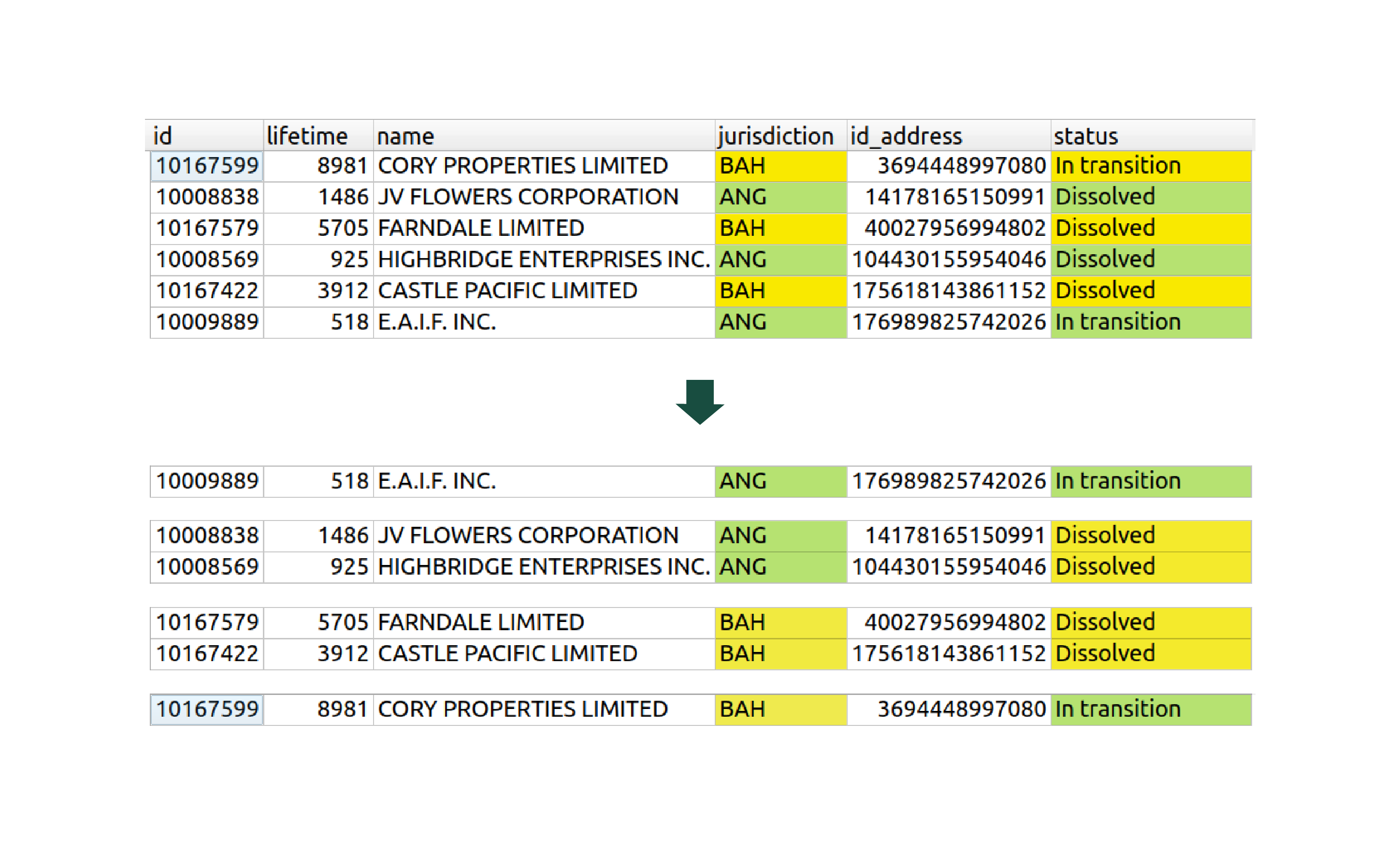
Partitionnement selon les colonnes [ jurisdiction, status ]
Ici par exemple, les sociétés du 2e groupe ont toutes le statut “Dissolved” (dissoutes), et proviennent de la juridiction Anguilla (dont le code est “ANG”).
Appliquez des fonctions d'agrégation
Une fois les agrégats formés, il faut bien en faire quelque chose !
C'est là qu'intervient la fonction d'agrégation. Son rôle est de prendre en entrée un groupe de plusieurs lignes, d'effectuer un calcul sur celles-ci, puis de retourner une unique valeur pour chacun des groupes.
Parmi les fonctions d'agrégation, on peut trouver la moyenne, le minimum, le maximum, la somme, etc.
Par exemple, on peut appliquer la fonction qui calculera la moyenne des durées de vie des sociétés (lifetime). On l'applique d'abord au groupe des sociétés de la juridiction ANG et du statut “In transition”, puis au groupe des sociétés de ANG ayant le statut “Dissolved”, etc.
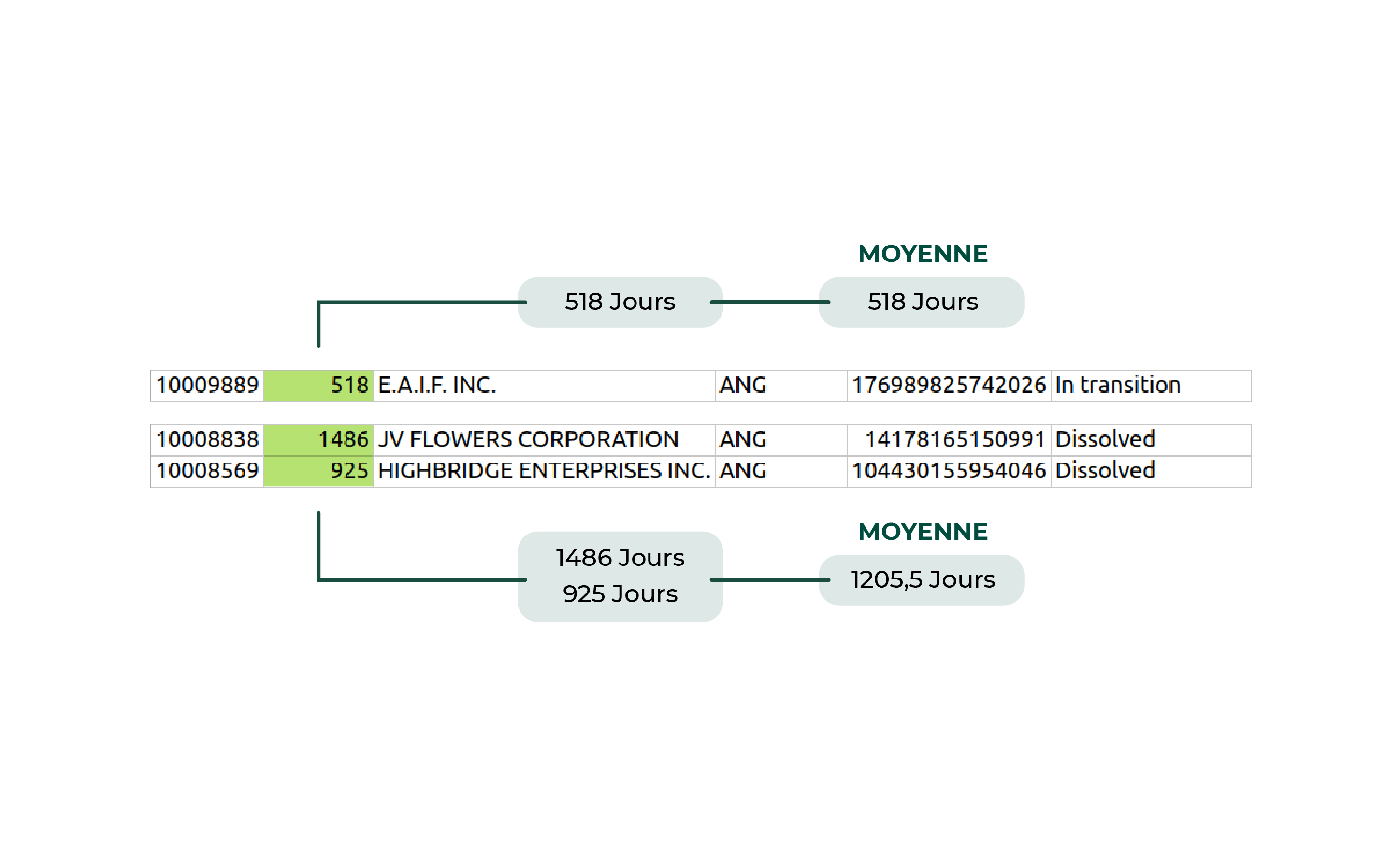
En général, une fonction d'agrégation prend en entrée une liste et renvoie une unique valeur. Par exemple, pour calculer la durée de vie moyenne des sociétés, la fonction moyenne prendra en entrée la liste des durées de vie des sociétés de l'agrégat, et retournera la moyenne de cette liste. C'est ce qui se passe sur l'image ci-dessus.
Mais il est également possible de trouver des fonctions d'agrégation qui prennent plusieurs colonnes en entrée (donc plusieurs listes) ou parfois même l'ensemble des colonnes d'une table.
Voici donc le résultat d'une agrégation avec partitionnement selon les colonnes status et jurisdiction , en appliquant deux fonctions d'agrégation :
La fonction moyenne (en anglais average, notée avg) sur la colonne
lifetime.La fonction compter (en anglais count), qui compte le nombre de sociétés de l'agrégat.
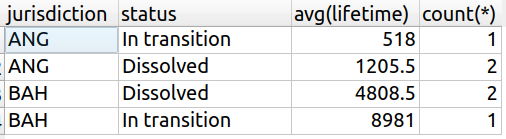
Grâce à ce résultat, on peut dire que la durée de vie moyenne des 2 sociétés dissoutes des Bahamas est de 4 808,5 jours. C'est la classe, non ?
Déterminez la clé primaire après une agrégation
Vous vous souvenez, lors d'un précédent chapitre, nous avions dit qu'il est très important de connaître la potentielle clé primaire d'une table ! Je vous propose ici un petit raisonnement pour trouver la clé primaire d'une table issue d'une agrégation.
La nature des objets représentés par une ligne avant l'agrégation (ici : une société) ne sera pas la même qu'une ligne après agrégation (ici : un ensemble de sociétés).
Vous me voyez venir ? Si la nature des lignes a changé, alors la clé primaire a probablement aussi changé !
Mais heureusement, c'est assez simple. Comme on groupe par status et jurisdiction , alors il ne peut pas y avoir (dans le résultat) 2 lignes qui ont à la fois le même statut et la même juridiction (bah oui, sinon elles auraient été regroupées en une !). Il y a donc bien unicité, et on peut prendre comme clé primaire [status, jurisdiction] !
Agrégez vos données avec GROUP BY
Voici comment écrire la requête SQL qui a permis d'obtenir la table précédente :
SELECT
jurisdiction,
status,
avg(lifetime),
count(*)
FROM
entity
GROUP BY
jurisdiction, statusNous avons placé les colonnes de partitionnement (ici status et jurisdiction ) derrière le mot clé GROUP BY, et les fonctions d'agrégation count() (en français "compter") et avg() (mis pour “average”, soit “moyenne”) dans le SELECT. Optionnellement, on peut aussi ajouter dans le SELECT les colonnes de partitionnement comme ici.
Voilà, vous savez tout !
Tout ? Non… vous allez voir que quand on fait une agrégation, il faut faire très attention à ce que l'on met dans le SELECT. Voici la démonstration en vidéo :
Dans le SELECT, on peut faire appel à une fonction d'agrégation uniquement si chacune des autres colonnes :
résulte elle aussi d'une fonction d'agrégation ;
OU
est une colonne de partitionnement présente dans le GROUP BY.
Continuez notre investigation
Prêt à reprendre la grosse requête du chapitre précédent pour continuer l'enquête ? Courage, vous en êtes capable ! Dans cette vidéo, vous allez analyser l'activité des 2 intermédiaires que nous avons trouvés précédemment.
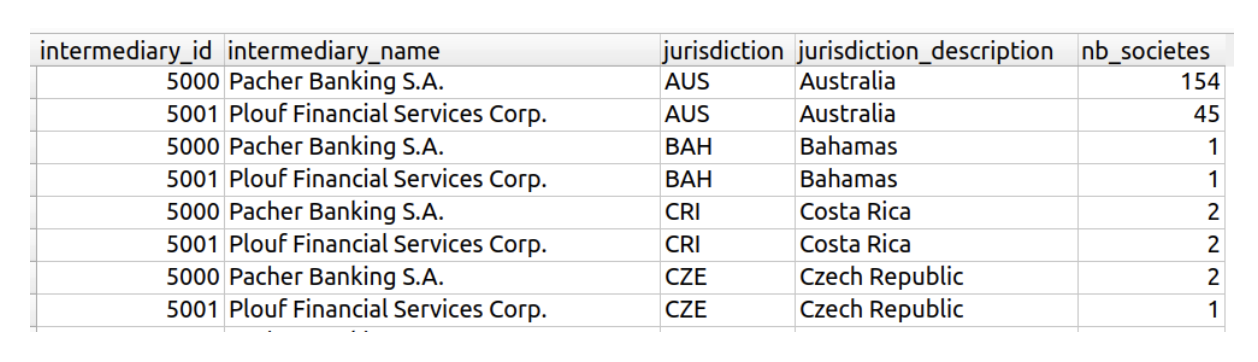
Voici la requête utilisée dans la vidéo :
SELECT
i.id as intermediary_id,
i.name as intermediary_name,
e.jurisdiction,
e.jurisdiction_description,
count(*) as nb_societes
FROM
intermediary i,
assoc_inter_entity a,
entity e
WHERE
a.entity = e.id
AND a.inter = i.id
AND (i.id = 5000 OR i.id = 5001)
GROUP BY
i.id, i.name, e.jurisdiction, e.jurisdiction_description ;Voici la table que nous obtenons en résultat :
À vous de jouer

Contexte
Ouh là, vous avez été un peu trop vite avec la requête ci-dessus : elle vous donne le nombre de sociétés créées par chacun des 2 intermédiaires dans chacune des juridictions. Mais il aurait fallu savoir combien de sociétés ont créé ces 2 intermédiaires, quelle que soit la juridiction, pour avoir une vue plus générale ! En effet, quand on analyse des données, on va toujours “du général au particulier” : on regarde d'abord les caractéristiques globales du jeu de données, pour ensuite affiner et rechercher des informations plus spécifiques.
Vous souhaitez aussi connaître le début des activités des intermédiaires, en allant chercher pour chacun d'eux la date de création de la première société qu'ils ont créée.
Consignes
Voici la requête écrite précédemment :
SELECT
i.id as intermediary_id,
i.name as intermediary_name,
e.jurisdiction,
e.jurisdiction_description,
count(*) as nb_societes
FROM
intermediary i,
assoc_inter_entity a,
entity e
WHERE
a.entity = e.id
AND a.inter = i.id
AND (i.id = 5000 OR i.id = 5001)
GROUP BY
i.id, i.name, e.jurisdiction, e.jurisdiction_description ;Modifiez-la en :
supprimant la notion de juridiction (c'est-à-dire en ne groupant que par intermédiaire) ;
ajoutant une colonne donnant la valeur minimale de la colonne
incorporation_date(donnant la date de création des sociétés) ; cette colonne sera renomméepremiere_activite.
Voici le résultat attendu :
intermediary_id | intermediary_name | nb_societes | premiere_activite |
5000 | Pacher Banking S.A. | 281 | 1990-04-20 |
5001 | Plouf Financial Services Corp. | 126 | 1990-05-18 |
Vérifiez votre travail
Ici, il faut supprimer du GROUP BY les colonnes relatives à la juridiction.
Il faut aussi penser à les supprimer du SELECT, car elles ne résultent pas d'une fonction d'agrégation, et elles ne sont plus dans le GROUP BY.
Pour ajouter la nouvelle colonne, il faut ajouter
min(incorporation_date)dans le SELECT.
Voici la requête à écrire pour obtenir votre résultat :
SELECT
i.id as intermediary_id,
i.name as intermediary_name,
count(*) as nb_societes,
min(incorporation_date) as premiere_activite
FROM
intermediary i,
assoc_inter_entity a,
entity e
WHERE
a.entity = e.id
AND a.inter = i.id
AND (i.id = 5000 OR i.id = 5001)
GROUP BY
i.id, i.name;En résumé
Les deux composantes de l'agrégation sont :
les colonnes de partitionnement ;
la/les fonction(s) d'agrégation.
Une fonction d'agrégation classique prend plusieurs valeurs en entrée, et renvoie une unique valeur.
On place les fonctions d'agrégation dans le SELECT, et les colonnes de partitionnement dans le GROUP BY.
Le résultat d'une agrégation donne une table avec des lignes qui ne représentent pas les mêmes objets qu'avant l'agrégation. La clé primaire est donc modifiée. Elle est composée de colonnes de partitionnement, et est parfois simplifiable.
Dans le SELECT, on peut faire appel à une fonction d'agrégation uniquement si chacune des autres colonnes résulte elle aussi d'une fonction d'agrégation, ou bien si elle est une colonne de partitionnement présente dans le GROUP BY.
Maintenant que nous savons dans quels pays nos intermédiaires ont créé des activités, on va maintenant chercher où ils ont été le plus actifs !
